

С помощью встроенных формул, таких как IMPORTHTML и IMPORTXML, можно загружать контент в таблицы для дальнейшей обработки. Это похоже на работу программы-парсера, только проще и доступнее.
Давайте разберём, как именно использовать Google Таблицы для извлечения данных с сайтов.
Импорт через IMPORTHTML
IMPORTHTML — формула для импорта HTML-кода целой веб-страницы или её фрагмента. Это удобно, когда нужно получить содержимое сайта в табличном виде.
Например, можно импортировать список новостей или товаров интернет-магазина. Для этого достаточно ввести формулу =IMPORTHTML(ссылка_на_страницу; «table», индекс_таблицы) в ячейку.
Чтобы использовать IMPORTHTML, создайте новый лист в Google Docs и введите формулу =IMPORTHTML(url; «table»;num). Где:
- url — это адрес импортируемой веб-страницы;
- table — указывает, что нужно импортировать табличные данные;
- num — номер таблицы на странице для импорта.
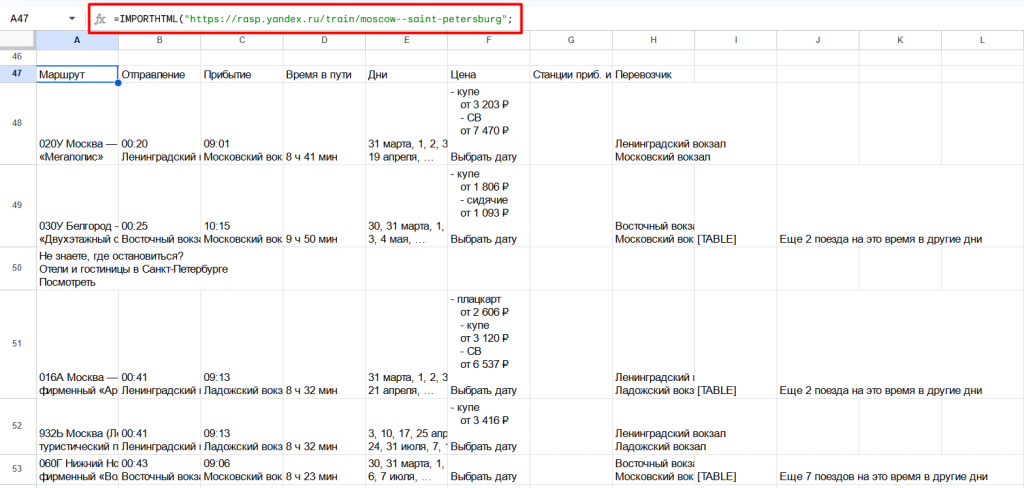
Например, импортируем расписание поездов:
- =IMPORTHTML(«https://rasp.yandex.ru/train/moscow—saint-petersburg»; «table»;1).
Эта формула импортирует первую таблицу на странице rasp.yandex.ru. В результате получаем актуальное расписание поездов, которое можно проанализировать и обработать в таблице.
Рассмотрим более подробный пример парсинга курсов валют с сайта ЦБ РФ.
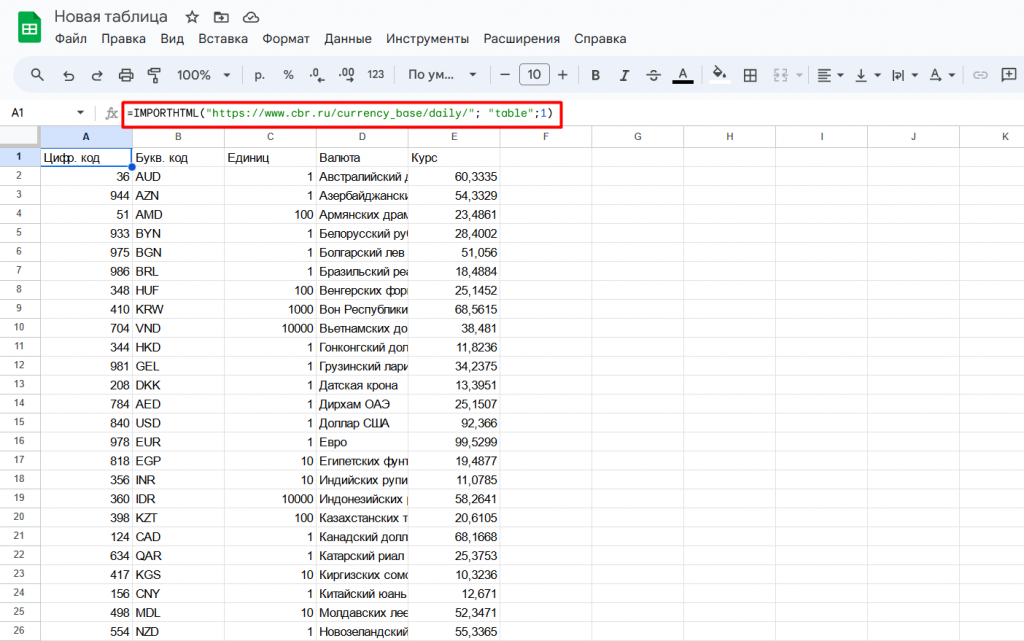
Создаём чистый лист в Google. Далее в ячейку вставляем формулу:
- =IMPORTHTML(«https://www.cbr.ru/currency_base/daily/»; «table»;1).
Она импортирует первую таблицу с главной страницы курсов валют ЦБ РФ.
Также Google предоставляют инструменты для анализа импортированных данных: графики, диаграммы, фильтры.
Кроме IMPORTHTML есть и другие полезные формулы для импорта данных, например, IMPORTDATA и IMPORTRANGE. Их можно использовать для парсинга страниц без табличной структуры.
Извлечение данных через IMPORTXML
Если нужно извлечь конкретные данные, а не фрагмент страницы, то используется IMPORTXML. Эта формула позволяет гибко настраивать поиск и парсинг информации.
Например, можно получить список заголовков и дат всех новостей на странице:
- =IMPORTXML(ссылка_на_страницу; «//h2|//span[@class=’date’]»).
Или извлечь конкретный параметр товара, например цену:
- =IMPORTXML(ссылка_на_страницу; «//span[@itemprop=’price’]»).
С помощью IMPORTXML можно решать более сложные задачи по сбору и анализу данных.
Внимание! Формулы выше не универсальны. Под каждый сайт и набор параметров нужно создавать индивидуальный запрос: в этом нам поможет ИИ от OpenAI.
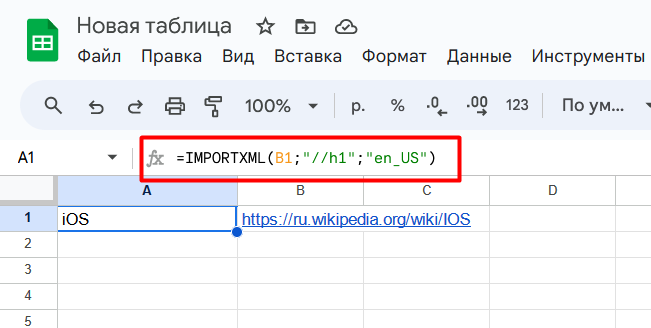
Предположим, нужно спарсить заголовок статьи Википедии:
- Скопируйте ссылку на главную страницу: https://ru.wikipedia.org/wiki/IOS.
- Откройте Google Таблицы и создайте новый лист.
- В ячейку А1 вставьте формулу:
=IMPORTXML(https://ru.wikipedia.org/wiki/IOS;»//h1″;»en_US«).
В первой строке первого столбца должен отобразиться заголовок.
Возможности IMPORTXML гораздо шире:
- Можно вытащить любые данные, к которым есть доступ через XPath запрос.
- Результаты можно фильтровать, сортировать, упорядочивать.
- Можно делать рекурсивный парсинг, обращаясь к выгруженным данным.
С помощью функций Google Sheets можно автоматизировать сбор и обработку информации с сайтов.
Как использовать чат-бот для парсинга веб-страниц
ChatGPT решает множество задач, которые раньше требовали знаний и навыков программирования. Теперь достаточно дать чат-боту подробные инструкции — и он сгенерирует нужный код или скрипт.
Например, если задать ChatGPT вопрос «Как с помощью функции IMPORTXML в Google Таблицах извлечь заголовок веб-страницы в HTML?», он мгновенно выдаст готовую формулу для использования. Но это довольно простая задача, с которой можно справиться и без чат-бота.
А как быть, если нужно извлечь данные, структура которых менее стандартна? Попробуем разобрать на примере.
Постановка задачи
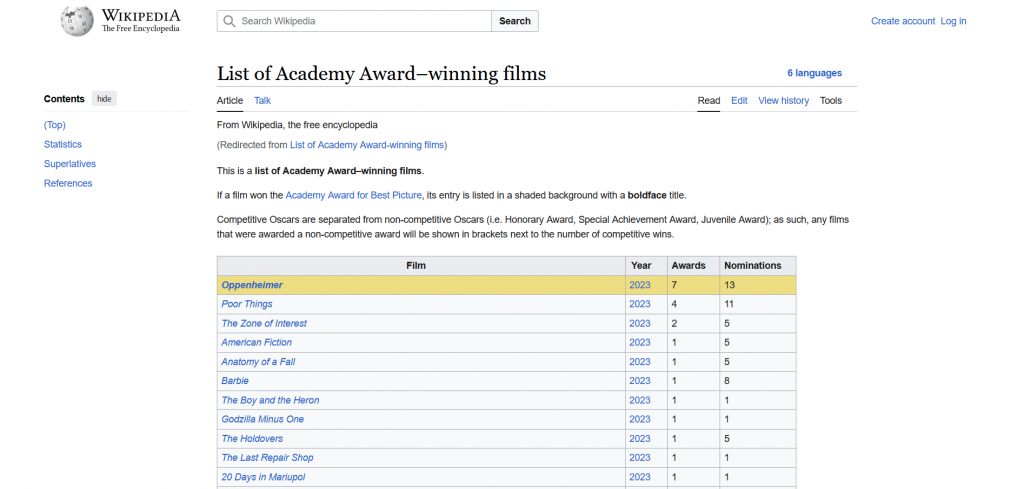
Пусть нужно извлечь данные с Википедии, о фильмах удостоенных наград Американской киноакадемии:
- Названия фильмов.
- Год выпуска.
- Количество наград.
- Количество номинаций.
Попытка решения с ChatGPT
При составлении запросов для чат-бота потребовалось несколько попыток, чтобы максимально подробно сформулировать задачу. ChatGPT стремился быстро дать какой-то результат, но не полностью соответствующий заданию.
На первых попытках чат-бот вернул всего 7 фильмов с заголовками и ссылками. После доработки запроса он смог выдать 1372 строк с ссылками.
Оставалось добавить награды и номинации. Но здесь чат-бот допустил ошибку, проигнорировав указания и сгенерировав свои, неточные значения.
При повторной попытке с загрузкой копии HTML-страницы ChatGPT также не справился с задачей. Проблема, по его словам, заключалась в сложной структуре и большом объёме страницы.
Решение с помощью Google Sheets
Далее была предпринята попытка решить задачу с использованием функции IMPORTXML в Google Таблицах.
На этот раз ChatGPT сгенерировал формулы для извлечения названий, дат, наград и номинаций.

Вот примеры формул, предложенных чат-ботом:
- =IMPORTXML(«ссылка на страницу»;»xpath для заголовка»;);
- =IMPORTXML(«ссылка на страницу»;»xpath для года выпуска»;);
- =IMPORTXML(«ссылка на страницу»;»xpath для наград»;);
- =IMPORTXML(«ссылка на страницу»;»xpath для номинаций»;).
С помощью этих формул данные были представлены в столбцах A, B, C и D.
Ограничения Google Таблиц
Возможности Google Sheets впечатляющие, учитывая, что это бесплатный онлайн-сервис. Однако есть и ограничения:
- Максимум 50 000 ячеек с данными за импорт. Для больших объёмов нужно использовать скрипты.
- Нет гибкой настройки частоты импорта. Данные обновляются только по запросу.
Google Таблицы отлично подходят для небольших объёмов данных. Пользоваться функциями импорта гораздо проще, чем изучать язык программирования и разрабатывать собственные скрипты.
В завершение познакомимся с онлайн-сервисов по ускорению индексации SpeedyIndex. В последнем обновлении было добавлено:
- Проверка сайта в индексе Google.
- Экспорт ссылок из карты сайта.
- Отправка списка ссылок в виде сообщения.
Проверка происходит по 4 запросам: site:URL, inurl:URL, URL, «URL». На баланс каждого пользователя было зачислено 50 ссылок для тестирования обновления. Отчёт об индексации поступает через 72 часа.



